Zawgyi နှင့် Unicode ရှေးဟောင်း၊ နှောင်းဖြစ်ကို ကျွန်တော်သိသလောက် ပြောရမယ်ဆိုရင် Unicode စနစ်ထဲကို မြန်မာစာစနစ် အပြည့်အဝမရောက်ခင်က Win Myanmar ကွန်ပျူတာလက်ကွက်ရိုက်ပုံစနစ်နှင့် တူညီပြီး Internet ပေါ်မှာ မြန်မာစာကိုဖေါ်ပြပေးနိုင်တဲ့ Zawgyi ဆိုတဲ့ မြန်မာစာစနစ် ပေါ်ထွက်လာခဲ့တယ်၊ အဲ့အချိန်တုန်းက blog ခေတ်တစ်ခုဖြစ်ခဲ့တယ် blogger တွေဟာ ဒီစနစ်ကို အသုံးပြုပြီး blogspot တို့ wordpress တို့ပေါ်မှာ စာတွေ၊ သတင်းတွေ ရေးခဲ့ကြတယ်။
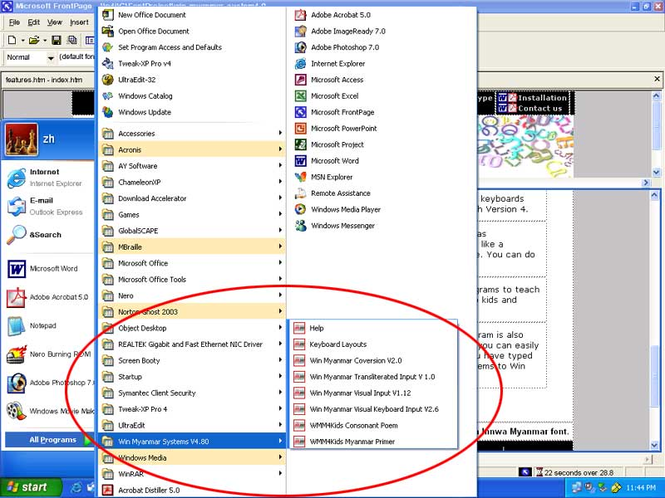 Windows XP ထဲမှာ Install လုပ်ထားတဲ့ Win-Myanmar Version တစ်ခု
Windows XP ထဲမှာ Install လုပ်ထားတဲ့ Win-Myanmar Version တစ်ခု
 ဒါကတော့ အားလုံးသိပြီးသား Zawgyi Keyboard Layout
ဒါကတော့ အားလုံးသိပြီးသား Zawgyi Keyboard Layout
ကွန်ပျူတာလောကမှာ Zawgyi မြန်မာစာစနစ်ရဲ့ ကျေးဇူးရှိပါတယ်။ နောက်ပြီး Zawgyi နှင့် Unicode တိုက်ပွဲတွေလည်း ဖြစ်ခဲ့ကြတယ်။ ဒါပေမယ့် အခုအချိန်မှာတော့ Zawgyi အစား Unicode ကိုပြောင်းလဲအသုံးပြုဖို့ အချိန်ရောက်ပါပြီ။ တကယ်တော့ ဒီ Zawgyi နှင့် Unicode စနစ်တွေဆိုတာ ကိန်းဂဏန်းတွေပဲသိတဲ့ ကွန်ပျူတာကို မြန်မာစာသိအောင် လုပ်ဆောင်ပေးတဲ့စနစ် (သို့) နည်းပညာစကားအရပြောမယ်ဆိုရင် Character Set အတွက် Encoding စနစ်ဖြစ်ပါတယ်။
Character Set အတွက် Encoding စနစ်
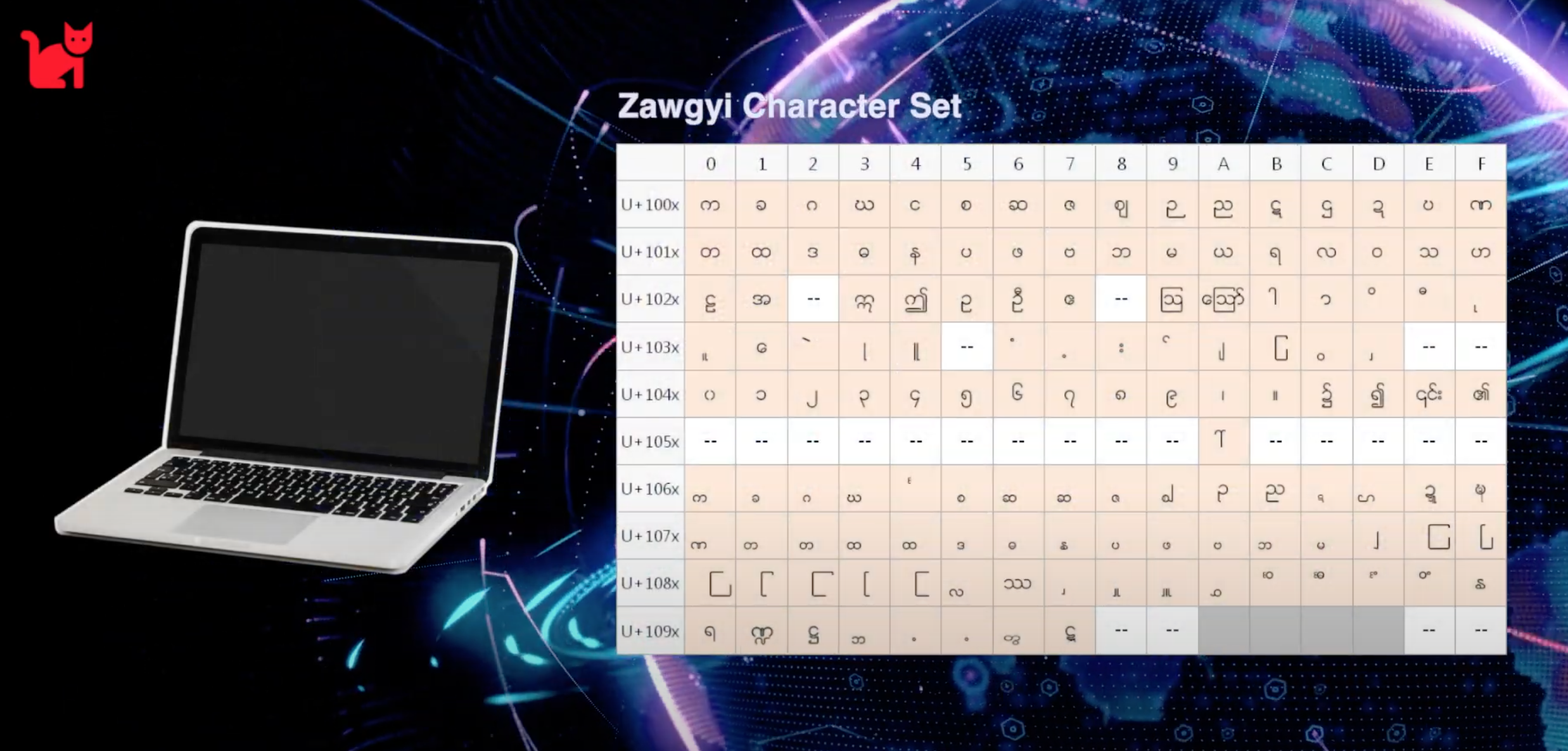 Zawgyi Character Set
Zawgyi Character Set
Encoding စနစ်တစ်ခုကို ဖန်တီးဖို့ဆိုရင် ဘာသာစကားတစ်ခုမှာရှိတဲ့ စကားလုံးတွေ၊ သင်္ကေတတွေကို ကွန်ပျူတာသိတဲ့ Code Point တစ်ခုချင်းစီမှာ နေရာချထားပေးရပါတယ်။
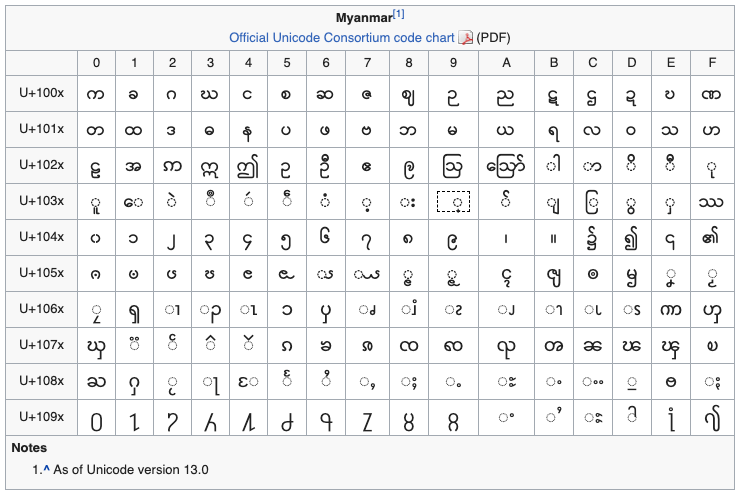 Character တစ်ခုချင်းစီအတွက် Code Point များချထားပုံ
Character တစ်ခုချင်းစီအတွက် Code Point များချထားပုံ
FontLab ထဲမှာ Myanmar Unicode ကိုဖွင့်ကြည့်လိုက်ရင် Code Point တွေကို အခုလိုအလွယ်တကူ မြင်တွေ့ရမှာ ဖြစ်ပါတယ်။
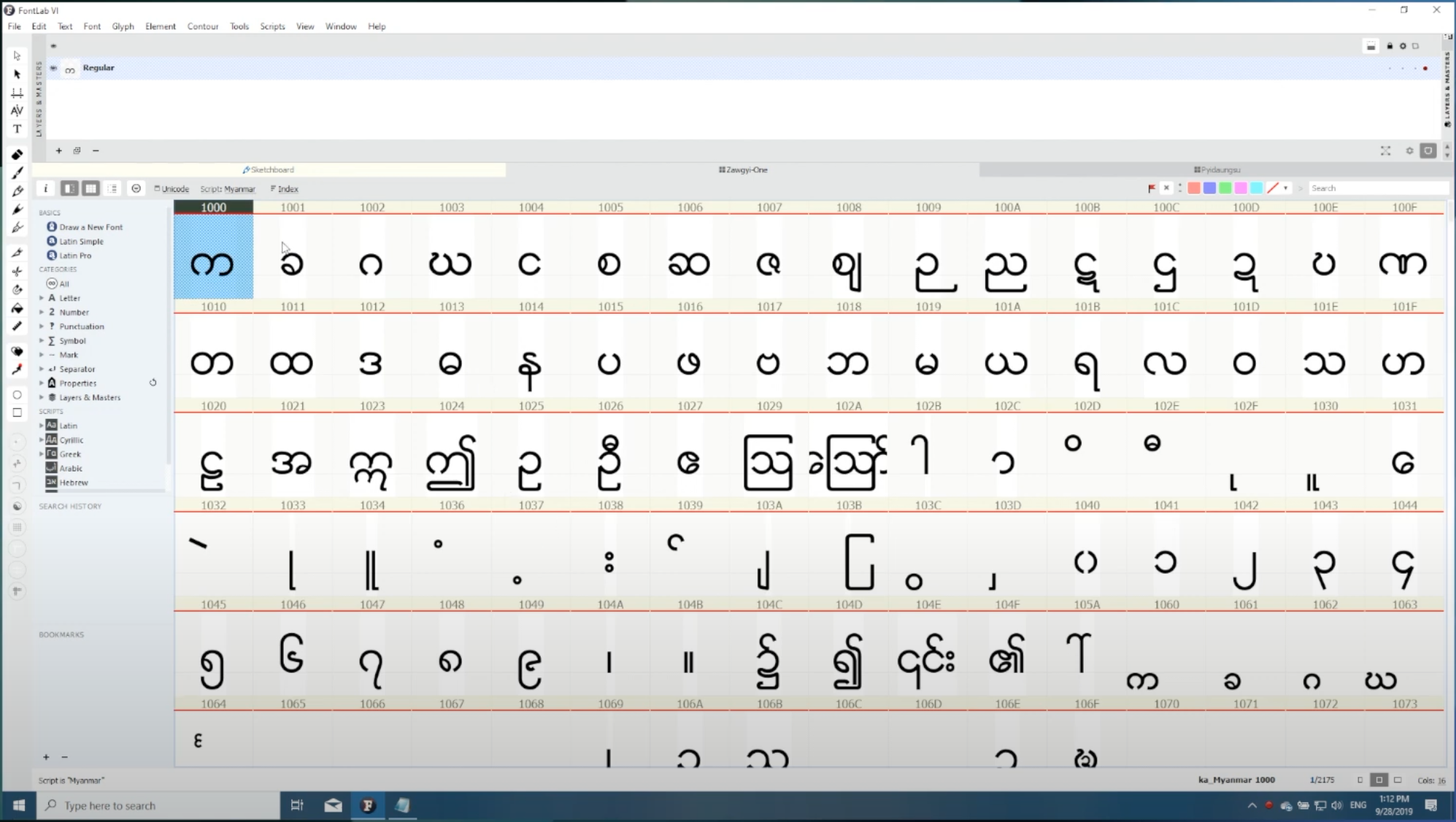 Unicode ရဲ့ Code Point တွေကို FontLab မြင်တွေ့ရပုံ
Unicode ရဲ့ Code Point တွေကို FontLab မြင်တွေ့ရပုံ
နောက်ပြီး ဘာသာစကားကို ကွန်ပျူတာထဲ အလွယ်တကူ ထည့်သွင်းနိုင်အောင် လက်ကွက်ပုံစံ စနစ်တစ်ခု ဖန်တီးရပါတယ်။ လက်ကွက်ပုံစံစနစ်ဆိုတာ Keyboard Layout ဖြစ်ပါတယ်။ လက်နဲ့စာရွက်ပေါ်မှာ စာရေးရင် လက်ရေးဖြစ်သလို၊ ကွန်ပျူတာ (သို့) ဖုန်းနှင့် စာရေးမယ်ဆိုရင်တော့ လက်ကွက်နှိပ်ပြီးရေးရပါတယ်။ မြန်မာစာစနစ်အတွက် ဖန်တီးထားတဲ့ Encoding စနစ်နှစ်ခုဖြစ်တဲ့ Zawgyi နှင့် Unicode ရဲ့ ပြဿနာက မြန်မာအက္ခရာတွေကို Code Point တွေမှာ နေရာချထားပုံမတူတာရယ်၊ ဖန်တီးထားတဲ့ လက်ကွက်ပုံစံမတူတာရယ်ဟာ အဓိကပြသနာဖြစ်ပါတယ်။
Code Point မှာ စကားလုံးနှင့် သင်္ကေတတွေ နေရာချထားပုံ ကွဲပြားမှု
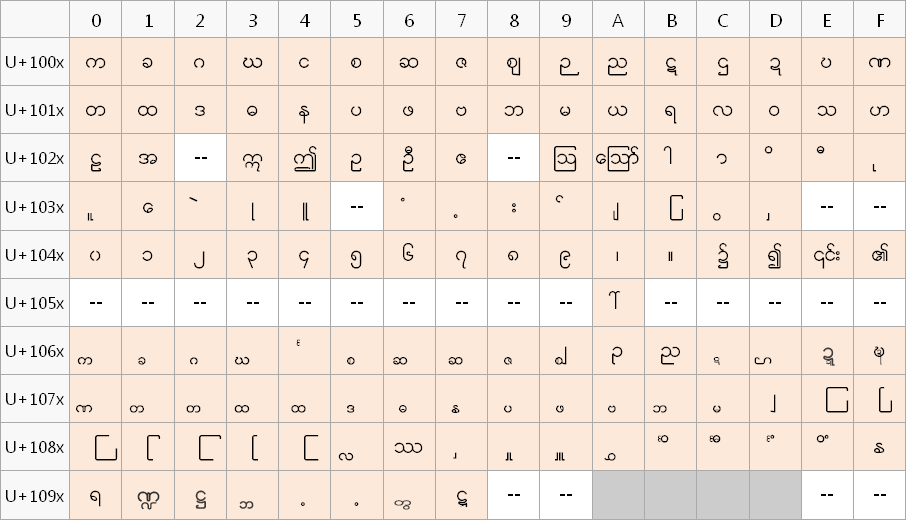 Zawgyi မှာ Character တစ်ခုချင်းစီအတွက် Code Point များချထားပုံ
Zawgyi မှာ Character တစ်ခုချင်းစီအတွက် Code Point များချထားပုံ
အထက်မှာပြထားတဲ့ Zawgyi Character Set ကိုကြည့်မယ်ဆိုရင်၊ အလွယ်တကူ သတိထားမိနိုင်တာက “ယရစ်” တွေကို Code Point တော်တော်များများမှာ သတ်မှတ်ထားတာကို သတိထားမိနိုင်ပါတယ်။ Zawgyi ရဲ့ Code Point သတ်မှတ်ချက်ကို ဥပမာအနေနှင့် ပြောရမယ်ဆိုရင် ယခင်က ပုံနှိပ်စက်တွေမှာ အသုံးပြုလေ့ရှိတဲ့ ခဲစာလုံးတွေကို သတ်မှတ်သလိုမျိုး မြန်မာစာ အက္ခရာတွေရဲ့ အရွယ်အစားကိုလိုက်ပြီးတော့ ဗျည်းနှင့်အခြားသင်္ကေတတွေရဲ့ အရွယ်အစားမျိုးစုံကို Code Point တွေမှာ သတ်မှတ်ထားတာမျိုး ဖြစ်ပါတယ်။ အဲ့ဒီမှာ အခြေခံ ပြဿနာကဘာလဲဆိုတော့…အချက်အလက်တွေကို သိမ်းဆည်းတဲ့အခါနှင့် ရှာဖွေတဲ့အခါမှာ၊ လိုချင်တဲ့အချက်အလက်ကို မရနိုင်တာမျိုးတွေနှင့် ကြုံတွေ့နိုင်တယ်။
ဥပမာ...
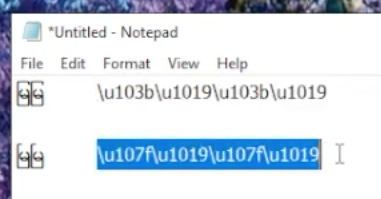 မတူညီတဲ့ Code Point တွေနှင့် မြမြ
မတူညီတဲ့ Code Point တွေနှင့် မြမြ
Zawgyi နှင့် မြမြ ဆိုတဲ့အမည်ကို ကွန်ပျူတာထဲ ထည့်သွင်းလိုက်မယ်ဆိုရင်၊ မြမြ ဆိုတဲ့အမည်ကို ကျွန်တော်တို့ နားလည်တာက နာမည်တစ်ခုတည်းလို့ နားလည်ပေမယ့်၊ အထက်မှာဖေါ်ပြထားသလို မြမြ အမည်ကို ထည့်သွင်းခဲ့မယ်ဆိုရင် Code Point တွေမတူတဲ့အတွက် ကွန်ပျူတာကတော့ အမည်နှစ်ခုလို့ နားလည်မှာဖြစ်ပါတယ်။ ထို့အတူ ရှာဖွေတဲ့အခါမှာလည်း ပုံစံနှစ်မျိုးနှင့် ရှာမှသာလျှင်၊ ကွန်ပျူတာအနေနှင့် ရှာဖွေပေးနိုင်မှာ ဖြစ်ပါတယ်။ နောက်ပြီး “တချောင်းငင်” နှင့် “နှစ်ချောင်းငင်” မှာလည်း အလားတူပြဿနာရှိတယ်။ Unicode မှာဆိုရင်တော့ ဒီလိုမျိုးပြဿနာမရှိပါဘူး။ နောက်ပြီး အခြားတိုင်းရင်းသား ဘာသာစကားတွေအတွက် Zawgyi မှာ Code Point သတ်မှတ်ထားခြင်း မရှိပါဘူး။ ဒါတွေဟာ Zawgyi ကို စံသတ်မှတ်ချက်နှင့် ကိုက်ညီမှုမရှိစေတဲ့ အကြောင်းအရင်းတွေကို ဖြစ်စေခဲ့ပါတယ်။
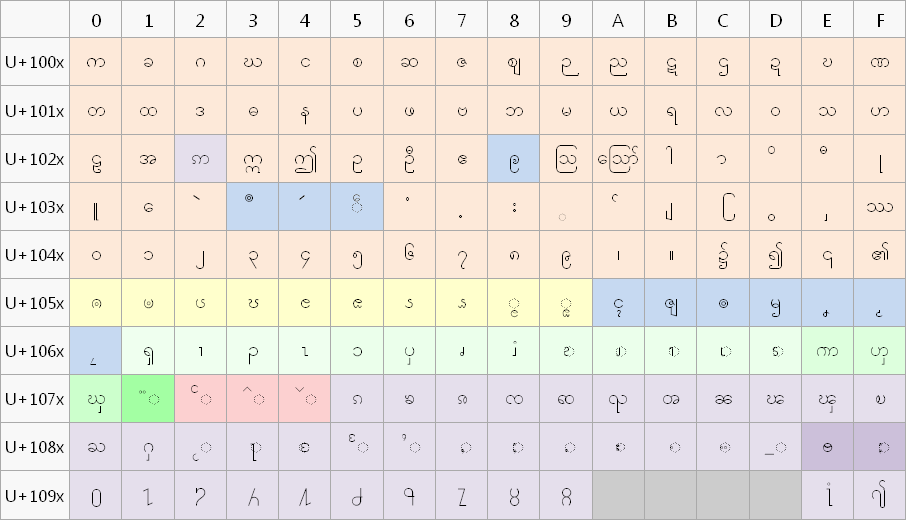 Unicode မှာ Character တစ်ခုချင်းစီအတွက် Code Point များချထားပုံ
Unicode မှာ Character တစ်ခုချင်းစီအတွက် Code Point များချထားပုံ
Unicode မှာတော့ Zawgyi ကဲ့သို့မဟုတ်ပဲ မြန်မာစာအက္ခရာအားလုံးအတွက် Code Point တစ်ခုခြင်းစီမှာ အတိအကျသတ်မှတ်ထားတာပဲ ဖြစ်ပါတယ်။ နောက်ပြီး တိုင်းရင်းသား ဘာသာစကားတွေလည်း ထည့်သွင်းထားပါတယ်။
လက်ကွက်စနစ် သတ်မှတ်ပုံ ကွဲပြားမှု
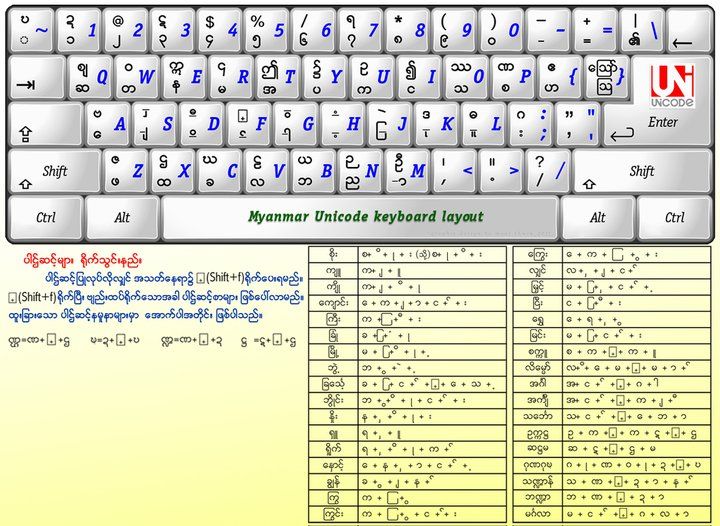 Unicode Keyboard Layout ပုံစံ
Unicode Keyboard Layout ပုံစံ
အစပိုင်းမှာ ကျွန်တော်ပြောခဲ့သလိုပဲ စာကို စာရွက်ပေါ်မှာ လက်နှင့်ရေးရင် လက်ရေးဖြစ်ပါတယ်။ စာကို ကွန်ပျူတာမှရေးရင် လက်ကွက်ရိုက်ပြီး ရေးကြရပါတယ်။ Keyboard Layout တွေကို ဟိုး…အရင်တုန်းကတော့ Microsoft Keyboard Layout Creator ကို အသုံးပြုပြီး ဖန်တီးခဲ့ကြတယ်။ Zawgyi နှင့် Unicode မှာ ကွဲပြားတဲ့ Keyboard Layout ရှိတဲ့အတွက်၊ ဥပမာ…Zawgyi နှင့် မြမြ ဆိုတဲ့အမည်ကို ကွန်ပျူတာမှာရိုက်ထည့်မယ်ဆိုရင် “ယရစ်” ကိုအရင်ရိုက်ထည့်ပြီးမှ၊ “မ” ကိုရိုက်ထည့်ရတာဖြစ်ပြီးတော့၊ Unicode ကတော့ သင်ပုန်းကြီး မြန်မာစာစနစ်ပေါ်မှာ အခြေခံထားတာဖြစ်တဲ့အတွက် “မ” ကိုအရင်ရိုက်ထည့်ပြီးမှ “ယရစ်” ကို ရိုက်ထည့်ရမှာ ဖြစ်ပါတယ်။ ဒါကြောင့် Unicode ဟာ လက်ကွက်ရိုက်တဲ့အခါမှာ ပိုပြီးအဆင်ပြေစေပါတယ်။
Unicode ကို ပြောင်းလဲသုံးစွဲမယ်ဆိုရင် ရနိုင်တဲ့အကျိုးကျေးဇူးတွေက
- တိုင်းရင်းသား ဘာသာစကားများ အသုံးပြုနိုင်ခြင်း
- သင်ပုန်းကြီး မြန်မာစာစနစ်အတိုင်း စာရိုက်နိုင်ခြင်း
- Operating System တွေမှာ အလွယ်တကူ ပြောင်းလဲသုံးစွဲနိုင်ခြင်း
စသည်တို့ပဲ ဖြစ်တယ်။